https://www.kaggle.com/c/kkbox-music-recommendation-challenge
WSDM - KKBox's Music Recommendation Challenge
Can you build the best music recommendation system?
www.kaggle.com
Kaggle의 지난 competition 중 음악 추천과 관련된 문제가 있길래 도전했습니다.
분석 기간은 포스팅 일자까지 포함하면 2020/06/01(월) ~ 2020/06/03(수)입니다.
1) 과제 및 데이터 소개
KKBox는 아시아 음악 스트리밍 사이트입니다. 데이터를 살펴보면 한국 음악도 간혹 보입니다. WSDM 2018년 과제가 KKBox에서 제공한 데이터를 바탕으로 음악을 추천해주는 모델을 만드는 것입니다.
데이터 파일은 총 6개로 7 zip으로 압축되어 있습니다. 압축을 해제하면 용량이 상당합니다.

submissions는 캐글에 제출하기 위한 파일을 관리하는 폴더로 제가 만든 것입니다. 그 외 나머지 CSV 파일을 가지고 음악 추천 과제를 수행해야 합니다.
각 파일과 그에 대한 내용은 캐글에 잘 설명되어 있는데, 정리하면 다음과 같습니다.


실제로 중요한 것은 train.csv입니다. 과제의 목적은 test.csv에 있는 msno의 사용자가 song_id의 노래를 한 달 안에 다시 들을지 판단하는 것입니다. 만약 한 달 안에 다시 듣는다면 target의 값은 1이 되고 그렇지 않으면 0이 됩니다.
songs.csv, memevers.csv, song_extra_info.csv 는 노래와 사용자에 대한 세부 정보를 담고 있습니다. 이를 사용한다면 성능 좋은 추천 시스템을 만들 수 있을 것입니다.
2) 추천 시스템 접근 방식
추천 시스템을 만드는 데 있어서 두 가지 접근 방식이 있습니다.
Collaborative Filtering (CF 방식)의 핵심은 나와 비슷한 성향의 사용자를 찾고, 해당 사용자의 선호를 기반으로 추천합니다.
Content Based (CB 방식)의 핵심은 아이템(과제에서는 노래) 자체의 특성을 바탕으로 내가 좋아하는 아이템과 유사한 아이템을 찾아서 추천합니다.
일반적으로 전자의 방식을 기반으로 추천 시스템을 구현합니다. 사용 데이터를 행렬로 만들고 이를 분해하여서 특징(feature)을 찾아내는 방식입니다. 하지만 CF 방식은 Cold-Start Problem, 즉 데이터가 없는 상황에서 추천하는 문제를 해결하기 어렵습니다. 처음 시스템에 가입한 사용자는 아이템에 대한 선호 데이터가 없으며, 처음 시스템에 등록된 아이템 역시 다른 사용자가 선호 여부를 판단하지 않았기 때문에 CF를 위한 데이터가 부재합니다.
따라서 실질적으로 CB 방식을 보완한 CF 방식, 즉 하이브리드 방식으로 추천 시스템을 구현하는 것이 일반적입니다. 본 과제 역시 최종적으로 하이브리드 시스템을 기반으로 해결하는 것을 목표로 합니다.
3) EDA(Exploratory Data Analysis
본격적인 과제 수행에 앞서서 데이터에 대한 기본적인 성질을 파악하도록 하겠습니다.


데이터 샘플을 확인한 결과 영어뿐만이 아니라 한자도 있으며 NaN 값도 보입니다. msno와 song_id는 긴 문자열로 객체를 충분히 식별할 듯합니다.
일단 주된 관심은 train.csv와 test.csv에 있으므로 train.csv와 test.csv에 있는 정보를 자세히 살펴봅시다.
source_system_tab KKBox 모바일의 기능을 의미합니다. 어떠한 이벤트를 통해서 사용자가 노래를 들었는지에 대한 정보입니다. train.csv와 test.csv에 있는 source_system_tab의 종류와 빈도를 살펴봅시다.
1. source_system_tab


train.csv와 test.csv 전체를 고려했을 때 my library 기능을 가장 많이 사용한 것으로 알 수 있습니다. target 값이 있는 train.csv에서 분포를 살펴보았을 때 my library에서 음악을 들었다면 한 달안에 다시 듣는 빈도가 높은 것을 알 수 있습니다.
또한 nan 값이 있는데 비교적 빈도 수가 적습니다. 하지만 그렇다고 my library에 포함시키기에는 target 값의 분포가 my library와 유사하지 않으므로 따로 imputation을 하지 않는 것이 좋아 보입니다.
2. source_screen_name
source_screen_name은 사용자가 보는 화면의 이름을 나타냅니다.


결과는 Local playlist more 이 앞도적으로 많고 target 값 역시 1로 만들 가능성이 높습니다. 이전과는 다르게 nan 값이 차지하는 비중(왼쪽 그래프의 3번째 주황색 막대)도 상당히 높은 것으로 보아 source_screen_name 사용은 유의해야 할 것 같습니다. 충분한 빈도수를 가지며 target 값을 가르는데 영향을 주는 Local playlist more, Online playlist more, Radio 값 만 사용하는 것을 고려해야 할 것 같습니다.
3. source_type
source_type은 모바일 애플리케이션 에서의 접근점을 의미합니다.

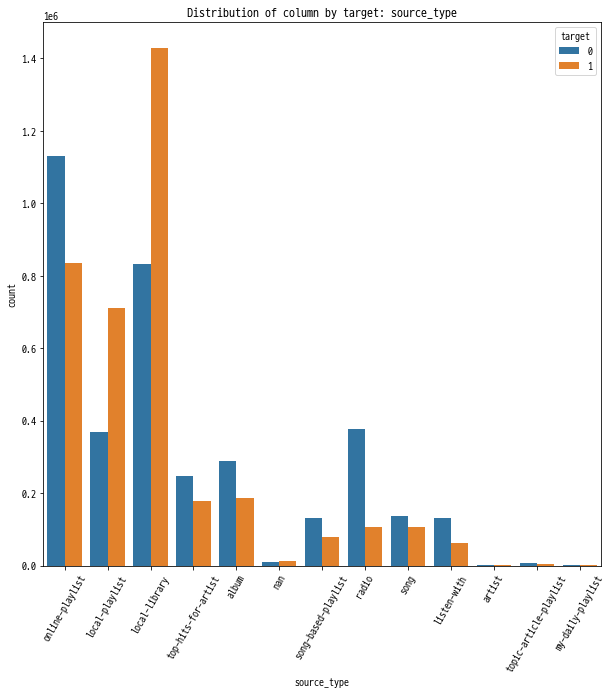
다른 두 정보(source_system_tab, source_screen_name)를 분석한 것과 비슷한 맥락으로 online-playlist, local-playlist, local-library, radio를 우선 주목하게 됩니다. 추가로 top-hits-for-artist, album 정도는 분석에서 고려하는 것도 괜찮아 보입니다.
4) 과제 수행: 추천 시스템 구현
본격적으로 test.csv를 예측하기 위한 추천 시스템을 만들도록 하겠습니다.
우선은 가장 기본적인 CF 방식의 Matrix Factorization을 활용할 예정입니다. 이 모델은 사실상 베이스라인이 될 것으로 기대합니다.
데이터 나누기: train-validation-split
모델의 공정한 성능 평가를 위해서 우선 train.csv에 데이터를 학습용과 검증용(validation)으로 구분하였습니다. 학습용 데이터의 수는 5,902,111이고 검증용 데이터의 수는 1,475,307입니다.입니다.
데이터 전처리
CSV에 있는 파일에서 msno, song_id, target 값 만을 사용합니다. 특히 msno, song_id는 각각 user와 item으로 간주하여서 user-item 행렬을 만드는 데 사용합니다. 일단 학습용 데이터에서 고유한 msno와 song_id를 찾고 이를 0부터 시작하는 인덱스와 대응시켜 사전을 만들어줍니다. 학습용 데이터에 있는 고유한 사용자의 수는 30,548이고, 아이템(노래)의 수는 324,428입니다.
(사용자 수) x (아이템 수)의 행렬을 만들고 성분의 값은 target 값에 의해서 결정합니다. 사용자가 아이템을 한 달 안에 들었을 경우(target = 1) 성분의 값은 1이고 아닌 경우(target = 0) 성분의 값은 -1입니다. 나머지 모든 값은 0이 됩니다.
상당히 거대한 행렬이므로 이를 프로그래밍적으로 구현할 때에는 scipy의 csr_matrix를 사용해 희소 행렬로 만들었습니다.
데이터 모델링
Matrix Factorization은 sci-kit learn에서 제공하는 TruncatedSVD 방식을 사용하였습니다. Matrix Factorization의 목적은 결국 (사용자 수) x (아이템 수) 행렬의 0 인 성분을 추론하기 위해서 (사용자 수) x (특징 수), (특징 수) x (특징 수), (특징 수) x (아이템 수)의 3 행렬로 분해하는 작업입니다. 분해된 행렬을 행렬 곱 연산을 해주면 (사용자 수) x (아이템 수) 행렬이 나오는데, 결과로 나온 행렬은 이전과 다르게 0인 성분이 추론되어 있습니다.
TruncatedSVD의 하이퍼 파라미터로는 특징 수 50, 반복 횟수 10으로 하였습니다. 학습에 많은 시간이 걸리므로 이보다 키우는 것은 무리입니다.
예측하기
검증용 데이터의 msno와 song_id에 대응하는 숫자 인덱스(학습용 데이터의 사전 활용)를 찾습니다. 만약 해당하는 숫자 인덱스가 없다면 일단을 target 값은 0으로 예측했습니다. CF 방식의 전형적인 문제이고 차후 이를 해결해나갈 것입니다.
찾은 숫자 인덱스를 바탕으로 분해된 행렬을 곱한 결과의 성분을 구합니다. 만약 해당 성분의 값이 0보다 크면 한 달 안에 다시 듣는다(target = 1)라고 예측합니다. 반면에 0보다 작으면 target 값은 0으로 예측합니다.
검증용 데이터를 바탕으로 했을 때, 약 65%의 정확률(0.6551782103657069)을 보였습니다.
따라서 학습용 데이터와 검증용 데이터를 모두 고려하여서 모델을 만들고 test.csv 에 적용하여서 제출용 CSV 파일을 생성합니다.

5) 향후 개선점
하이퍼파라미터 조정
TruncatedSVD 기반으로 최대한 올릴 수 있는 성능이 어디까지인지 확인하고자 합니다. 일단 하이퍼파라미터를 조정하여서 성능을 높일 수 있을 때까지 높입니다. 특히 target 값을 예측할 때 현재는 0을 기준으로 나누었지만 다른 값(threshold)을 사용해서 성능을 높여봅니다.
Content Based 접근
현재는 사용자의 아이템 사용 정보를 행렬로 만든 데이터만을 사용해서 예측하였습니다. 하지만 제공된 데이터는 노래와 사용자에 대한 상세한 데이터가 있습니다. EDA에서도 살펴보았듯이 target 값에 영향을 주는 정보가 상당히 많습니다. 이를 기반으로 추천 시스템의 향상을 기대합니다.
dhsong95/Kaggle-Data-Analysis
Contribute to dhsong95/Kaggle-Data-Analysis development by creating an account on GitHub.
github.com
'Kaggle 데이터 분석' 카테고리의 다른 글
| WSDM - KKBox's Music Recommendation Challenge (2): Exploratory Data Analysis (0) | 2020.06.14 |
|---|
