Modern Big Data Analysis with SQL 특화 과정 중 두 번째 강의 Analyzing Big Data with SQL의
두 번째 주차 SQL SELECT Essentials 내용 정리입니다.
|
SELECT는 SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT으로 구성한다
|
SQL SELECT 구조
단순한 Data Retrieval에서부터 Data Analysis까지 지원하는 SELECT는 다음과 같은 Building Block(Clause)으로 구성한다.
1) SELECT: 열 선택
2) FROM: 테이블 선택
3) WHERE: 조건에 따른 행 필터링
4) GROUP BY: Aggregation
5) HAVING: Aggregatino 필터링
6) ORDER BY: 정렬
7) LIMIT: 출력 결과 수 제한
SELECT Clause의 구성
SELECT Clause는 SELECT부터 시작해서 FROM 이전까지를 의미한다. 특히 SELECT 이후 선택되는 열 정보 Select List라고 한다. Select List는 상수(Literal), 테이블의 열(Reference), 수식 표현, 함수가 가능하다. 특별히 테이블에 있는 모든 열을 가리키기 위해서 * 표기를 사용한다.
Select List: 상수항(Literal)
Select List에 상수항이 사용될 경우 FROM 절이 필요하지 않다. SELECT의 실행 결과는 상수항이 그대로 나온다.

Select List에는 상수항과 테이블 열의 Reference가 동시에 사용될 수 있으며, 이러한 경우 행의 개수는 테이블 열의 Reference에 의해서 결정된다. 상수항은 개수만큼 반복해서 출력된다.

상수항은 연산에도 사용할 수 있다. 이때 데이터 타입에 맞는 연산을 사용하는 것이 중요하다.

만약 데이터 타입이 맞지 않는 경우 Type Casting이 필요하며, Explicit Type Casting과 Implicit Type Cast로 구분한다. Explicit Type Cast를 사용하는 것을 권장한다.
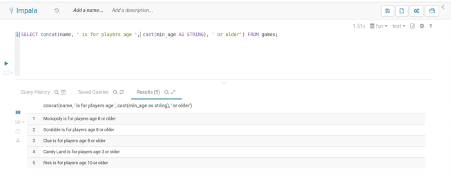
Select List: 함수(Built-in Functions)
SQL 엔진마다 주요한 함수들을 내장하고 있다. 특히 수학적 연산을 처리하는 함수와 문자열을 처리하는 함수가 공통적으로 구현되어있다.
1) 수학적 연산 처리: round(), ceil(), floor(), abs(), sqrt(), pow(), rand()
2) 문자열 연산 처리: length(), reverse(), substring(), concat(), trim(), pad(), upper(), lower()
데이터 타입의 종류
Numeric Data Type과 Character Data Type으로 구분할 수 있다.
1) Numeric Data Type: 정수(TINYINT, SMALLINT, INT, BIGINT), 실수(DECIMAL, FLOAT, DOUBLE)
2) Character Data Type: 문자열(CHAR, VARCHAR, STRING)
Column Alias
테이블의 헤더가 이름을 설정할 수 있다. 설정되지 않은 헤더는 Select List에 있는 문자를 그대로 쓰거나(Impala) 별도의 식별자(Hive)를 부여한다.

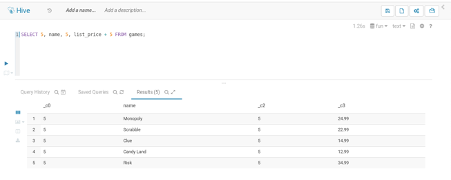
Column Alias를 부여하기 위해서 AS를 사용한다. AS를 생략해도 동작은 동일한 결과를 생성하지만 가동성과 일관성을 위해서 AS를 붙이는 것을 권장한다.


DISTINCT
DISTINCT는 SELECT와 같이 사용하여서 고유한 값의 행만을 출력한다.

FROM Clause
FROM 이후에 테이블을 지정하는 구문이다. 현재 연결된 Database(Active Database)에서만 테이블을 가져올 수 있다. Active Database와 무관하게 테이블을 가져오기 위해서는 databasename.tablename으로 명확히 기입해야 한다.
식별자 이름 짓기
테이블 이름, 데이터베이스 이름, 열 이름, 열의 별칭(Alias) 모두 식별자이다. 식별자는 알파벳, 숫자, 밑줄(_) 문자로 구성하며 첫 글자는 문자이다. 또한 SQL 엔진에서 사용하는 예약어를 식별자로 사용할 수 없다.
Non Interactive로 CLI 사용하기
1) Hive
A. 쿼리를 직접 실행: beehive --silent -u jdbc:hive2://localhost:10000 -e ‘SELECT * FROM fun.games;’

B. SQL 파일을 실행: beehive --silent -u jdbc:hive2://localhost:10000 -f commands.hql

2) Impala
A. 쿼리를 직접 실행: impala --quiet -q ‘SELECT * FROM fun.games;’

B. SQL 파일을 실행: impala-shell --quiet -f commands.sql

결과를 출력 형식과 같이 파일로 저장하기
1) Hive
A. CSV로 저장하기: beehive --silent -u jdbc:hive2://localhost:10000 –outputformat=‘csv2’ -f commands.hql > result.csv

2) Impala
A. CSV로 저장하기: impala-shell --quiet --delimited --output_delimiter=‘,’ --print_header -f commands.sql -o result.csv

'Coursera 강의 정리 > Modern Big Data Analysis with SQL' 카테고리의 다른 글
| S2 Analyzing Big Data with SQL - W4 Grouping and Aggregating Data (0) | 2020.09.21 |
|---|---|
| S2 Analyzing Big Data with SQL - W3 Filtering Data (0) | 2020.09.18 |
| S2 Analyzing Big Data with SQL - W1 Welcome to the Course (0) | 2020.09.16 |
| Foundations for Big Data Analysis with SQL - 10 빅 데이터 환경과 SQL (0) | 2020.09.15 |
| Foundations for Big Data Analysis with SQL - 07 빅 데이터 저장 및 처리 (Volume) (0) | 2020.09.15 |


