Modern Big Data Analysis with SQL 특화 과정 중 두 번째 강의 Analyzing Big Data with SQL의
네 번째 주차 Grouping and Aggregating Data 내용 정리입니다.
|
Aggregation은 다수의 행을 하나의 값으로 집계한다. |
Aggregation Function
Aggregation은 테이블의 여러 행을 합쳐서 하나의 값으로 집계(Aggregate)하는 것이다. SQL 엔진은 내장된 Aggregation Function으로 이를 지원한다. 대표적인 Aggregation Function으로는 COUNT, SUM, AVG, MIN, MAX가 있다.
Aggregation은 SELECT 구문에서 Select List로 활용될 수 있으며 Column Alias를 통해 별칭을 지을 수 있다. 하지만 WHERE 구문의 Condition으로는 Aggregation Function을 사용할 수 없으며, 이는 WHERE 구문은 개별 행 단위로 연산을 비교하기 때문이다. 다수의 행을 하나의 값으로 집계하는 연산인 Aggregation과 개별 행 단위의 연산인 Non-Aggregation(Scalar)를 혼용할 때에 주의해야 한다.

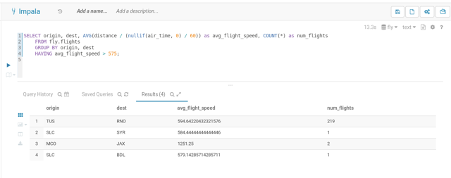
GROUP BY 구문
Aggregation은 테이블에 있는 모든 행에 대해서 Aggregate 한다. 하지만 테이블을 특정 그룹으로 구분하고, 그룹 별로 Aggregate 할 필요가 있다. 이를 위해서 GROUP BY 구문을 활용한다.
GROUP BY는 WHERE 구문 이후에 사용하며 GROUP BY List를 통해서 그룹 구성의 기준을 설정한다. GROUP BY List는 다수의 테이블 행 또는 Grouping Expression을 사용하는 것이 가능하다.

일반적으로 GROUP BY는 Aggregation Function과 같이 사용하지만, 질의에 따라서 별도로 사용할 수도 있다. 이러한 경우 Select List는 GROUP BY의 기준이 되는 테이블의 열을 설정해야 한다.
HAVING 구문
WHERE 구문에서는 Aggregation 값을 Condition으로 사용할 수 없다. Aggregation 값을 Condition으로 사용하기 위해서는 HAVING 구문이 있으며 GROUP BY 뒤에 위치한다. HAVING 구문의 문법은 WHERE 구문의 문법과 사실상 유사하다.
NULL 값 처리
구문마다 NULL 값을 처리하는 방식이 다르다.
1) Comparison Operation, Logical Operation에서 NULL과의 연산 결과는 기본적으로 NULL이다.
2) WHERE 구문에서 NULL 값은 선택되지 않는다.
3) Aggregation Function에서는 NULL을 제외하고 연산을 수행한다. 하지만 COUNT(*)와 같은 특수한 경우, NULL 값을 포함해서 모든 행의 개수를 반환한다.
4) GROUP BY 구문에서 NULL은 하나의 그룹으로 인정받아서 출력된다.

'Coursera 강의 정리 > Modern Big Data Analysis with SQL' 카테고리의 다른 글
| S2 Analyzing Big Data with SQL - W6 Combining Data (0) | 2020.09.23 |
|---|---|
| S2 Analyzing Big Data with SQL - W5 Sorting and Limiting Data (0) | 2020.09.22 |
| S2 Analyzing Big Data with SQL - W3 Filtering Data (0) | 2020.09.18 |
| S2 Analyzing Big Data with SQL - W2 SQL SELECT Essentials (0) | 2020.09.17 |
| S2 Analyzing Big Data with SQL - W1 Welcome to the Course (0) | 2020.09.16 |



